Going Agile: ETLFit (Testing)
This article is part of the Going Agile series of articles.
Articles published so far:
A very big thanks to etlaholic** for writing a PDI fixture for FitNesse (find original announcement here as well as a quick starter guide here)! As you can find out on the git page, the developer was very much inspired by Ken Collier’s book Agile Analytics (see my review here - once again, a book I highly recommend).
Unfortunately, I couldn’t hear enough people applauding the developer for this effort, so let me use this opportunity here to say: Well done and thanks a lot!
Unfortunately, topics such as testing do not earn much attention … when they really should.
Having said this, let’s learn a bit more about it.
**[@etlaholic: It would be great if you could mention your real name on your blog. You have some excellent post there of which you can be very proud of!]
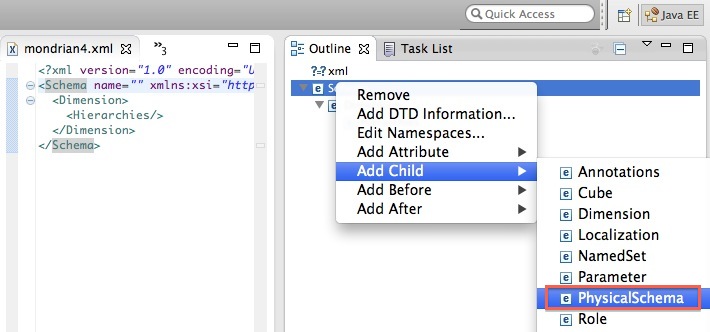
Initial Setup
I just briefly talk you through this:
Project webpage:
mkdir etlfit
cd etlfit
git clone git@github.com:falling-down/etlfit.git
Download dependencies
mkdir dbfit
cd dbfit
mv ~/Downloads/dbfit-complete-2.0.0.zip .
unzip dbfit-complete-2.0.0.zip
Adjust dbfit path in etlfit build.sh
cd ../etlfit
vi build.sh
Change
_HOME=~/
to
_HOME=../
This is not quite ideal, but I didn’t want to store the dependency files in my home directory.
It’s time to build ETLFit now:
sh ./build.sh
Next create the jar:
cd classes
jar -cvf etlfit.jar etlfit
Copy the resulting jar file to the lib directory of DbFit:
cp etlfit.jar ../../dbfit/lib
You can copy the provided EtlFit subwiki to your FitNesseRoot directory.
cd ..
cp -r test/EtlFit ../dbfit/FitNesseRoot/
Now start the Fitnesse Server (More details here): cd ../dbfit
sh ./startFitnesse.sh
Then check out the ETLFit example in your favourite web browser:
Read the content of this page properly!
Create your first test (very simple)
Read this page:
So let’s create a very basic test (without a Kettle job or transformation):
Just type in the base URL followed by a slash and the the filename in CamelCase:
This will directly open in the editor:
Insert the following lines into the editor window:
!path lib/*.jar
!|dbfit.PostgresTest|
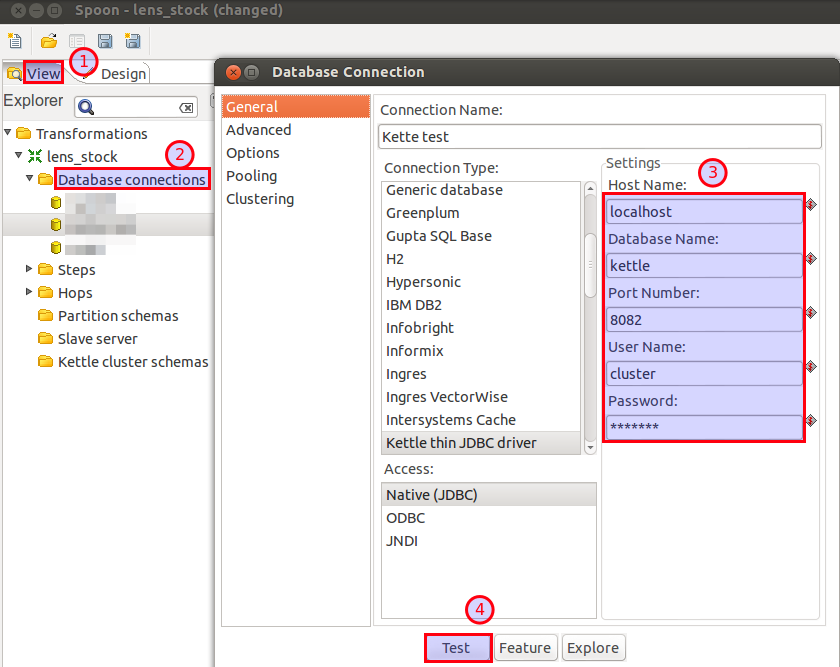
!|Connect|localhost|postgres|postgres|test|
!|Query| select 'test' as x|
|x|
|test|
The wiki lines above do the following (explanation line by line):
Load DBFit extension into FitNesse
Define database type
Define connection details
Define test query
Define result set columns that you want to use (you can cherry pick here)
Define the expected results
Please note that you have to adjust the database type and connection details according to your setup.
Once you save this it will look like this:
Then click Test in the top page menu bar and the test will be executed:![]()
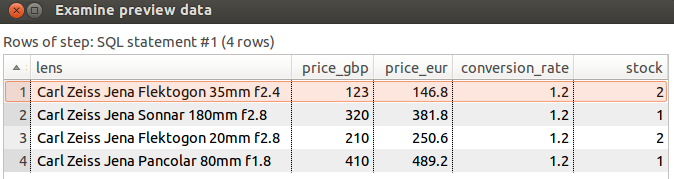
Test results are nicely presented on this page.
Another nice thing here is that the PostgreSQL driver is already installed, no additional setup and configuration necessary.
Putting it all together: Test with FitNesse and ETLFit
Let’s get a bit organized and set up a subwiki page:
Just leave the default content in the editor and then click Save.
The main wiki page (FrontPage) cannot be edited directly via the web browser, so open the following file:
export ETLFIT_HOME=/opt/pentaho/etlfit
vi $ETLFIT_HOME/dbfit/FitNesseRoot/FrontPage/content.txt
Note: Adjust the path to ETLFIT_HOME according to your setup.
Add:
!4 Subwikis
* .DbFit
* .MyProject
just before !-</div>-!
![]()
You should now see the links to the sub-wiki:
Click on the .MyProject link now and you will be presented with a fairly empty page:![]()
Next we have to let FitNesse know where to find the code to run the ETLFit fixtures. Click on Edit and this at the top (do not replace the default content):
!path lib/*.jar
Click Save next.
Next we will add the connection details and Kettle parameters to a dedicated Setup Page, which you can access via this URL:
localhost:8085/MyProject.SetUp
Config details stored in the SetUp page will be available to all pages in your subwiki.
# SetUp
!|dbfit.PostgresTest|
!|connect|localhost:5432|postgres|postgres|test|
!|etlfit.RunKettleFixture|
| set java home | /usr/lib/jvm/jdk1.7.0_15 |
| set kettle directory | /opt/pentaho/pdi/pdi-ce-5.0.1-stable/ |
| set etl directory | /home/dsteiner/Dropbox/pentaho/Examples/PDI/etlfit/ |
Please note that you have to adjust the configuration details according to your setup.
Make sure you add the trailing slashes to the last two parameters. There are more parameters available, this is just a starting point.
Save the page.
If you want to add a test page now, you can simple do this via the main menu: Add > Test Page:![]()
Provide a name for the test page. It is a good practice to suffix your test pages with Test and your test suite pages with Suite.
Now define the test details. First we clear the way (not really necessary), then we create the source and target tables. Next we insert the source dataset, then we execute the query with all required parameters and finally we define the result dataset query and what we expect as result dataset. In the end we drop all the tables again to keep everything tidy and rerunable.
### The set up
# create tables
!| execute | drop table if exists test.test4 |
!| execute | drop table if exists test.test5 |
!| execute | create table test.test4 ( city varchar(20), amount int ) |
!| execute | create table test.test5 ( city varchar(20), amount int, a char(1), b char(1) ) |
# insert rows
!| insert | test.test4 |
| city | amount |
| london | 30 |
| new york | 25 |
| miami | 45 |
# Remember to commit so that the transformation can act on the data.
!|commit|
### The execution
# Remember to declare the fixture name because DbFit is controlling the page.
!| etlfit.RunKettleFixture |
| run transformation | tr_test | with | !-
VAR_A=a,
VAR_B=b -! |
# Tip: If your transformation has many parameters you can use the !- -!
# enclosure to list them on multiple lines.
# This will help the readability of your test.
### The evaluation
!| query | select * from test.test5 |
| city | amount | a | b |
| london | 30 | a | b |
| new york | 25 | a | b |
| miami | 45 | a | b |
### The tear down
# Put your environment back the way you found it.
!| execute | drop table test.test4 |
!| execute | drop table test.test5 |
Save this now.
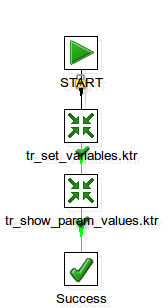
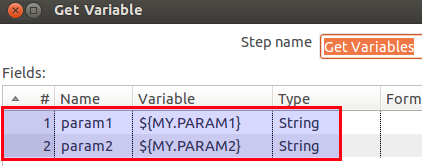
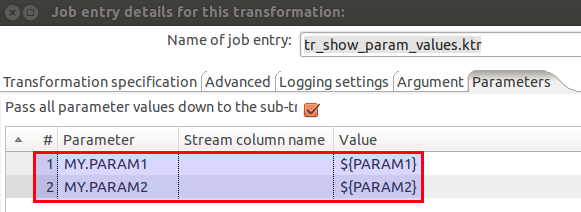
I created this very simple (and not very useful) transformation which accepts two parameters called VAR_A and VAR_B:
On the following page you will see an indicator that the test is running and once completed, you will be presented with the results:
More further down the page you can see which rows in the resultset were valid: ![]()
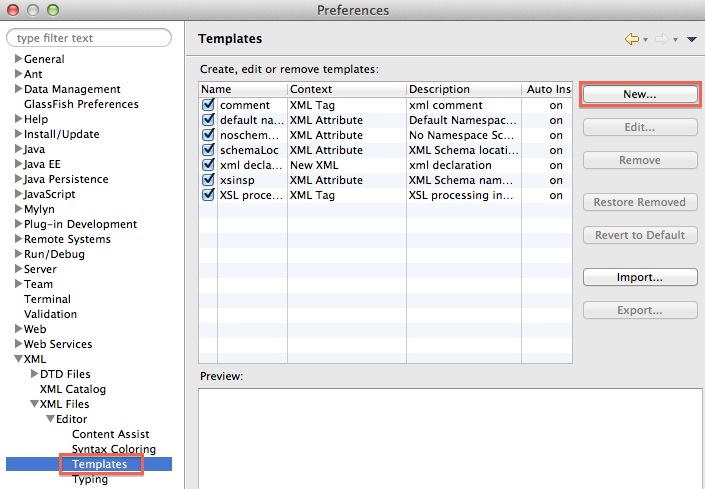
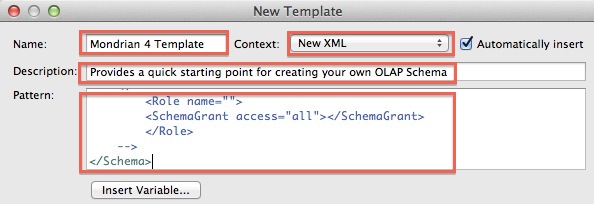
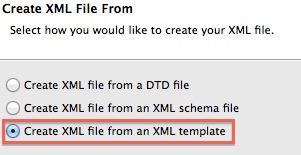
So you completed your first test setup and saw the results … quite impressive, isn’t it? This was of course just a simple example, go ahead and explore some of the other options. More useful tips and tricks can be found on etlaholic’s excellent Starter Guide. Final words
Using a Wiki page as a means of setting up a test is certainly a very interesting approach which makes the whole topic quite accessible to not so technical minded/skilled people as well. I do hope that ETLFit as well as DBFit gain some more momentum and support. DBFit currently doesn’t support many databases, so you might not be lucky enough to use it on every project you work on. But let’s hope that this changes in future! All in all, make sure you start using some sort of automated testing as soon as possible - I know it is a bit of a learning curve and it will take a bit of time, but once you start using ETLFit/DBFit in example, you won’t look back!